
Amazon recently convened an emergency meeting after AI-assisted code changes contributed to a string of outages, including one that caused a 99% drop in orders across North American marketplaces. The company is now rolling out a 90-day safety reset with stricter review processes.
Every company adopting AI coding tools is navigating this learning curve. Amazon’s experience is valuable because it makes the core problem visible at scale: when AI-generated code volume exceeds human review capacity and no structurally independent verification layer exists, failures propagate. The question isn’t whether to use AI for coding. It’s how to architect verification around it.
Four modes of AI in engineering
The developer writes code; the AI accelerates via autocomplete and suggestions.
Best for: Boilerplate, learning APIs, debugging, code review augmentation.
Failure mode: Linear scaling ceiling. Output bounded by human review speed.
Coined by Andrej Karpathy. Describe intent in natural language; the AI generates everything. Run it, see if it works, iterate.
Best for: Prototypes, internal tools, MVPs — low cost of failure.
Failure mode: Quality ceiling. Spectacular from 0 to 1. Unreliable from 1 to 100. Bugs accumulate silently.
Claude Code, Cursor Agent, Codex at their ceiling. The AI operates autonomously — reads files, runs tests, debugs, produces PRs.
Best for: Feature implementation from clear specs, bug fixes, refactoring, migrations.
Failure mode: Verification gap. Output exceeds review capacity. Same-context tests share the model’s blind spots.
You build the system that builds features. Design the pipeline, operate the pipeline.
Meta-engineering subsumes the other three and amplifies the verification gap. At this scale you need two things: adversarial verification for the code (a GAN problem), and human calibration for the system (an RLHF problem).
The tautological verification failure
When the same model generates code and then generates tests, the tests are epistemically contaminated. The model won’t test for edge cases it didn’t consider during implementation — the same reasoning process that missed them is now writing the tests. Context compression makes this worse: shared token optimization systematically suppresses the details most relevant to verification.
Result: tests that pass by construction. Zero adversarial pressure.
The GAN layer: adversarial verification
The inner loop. Builder and verifier, structurally independent.
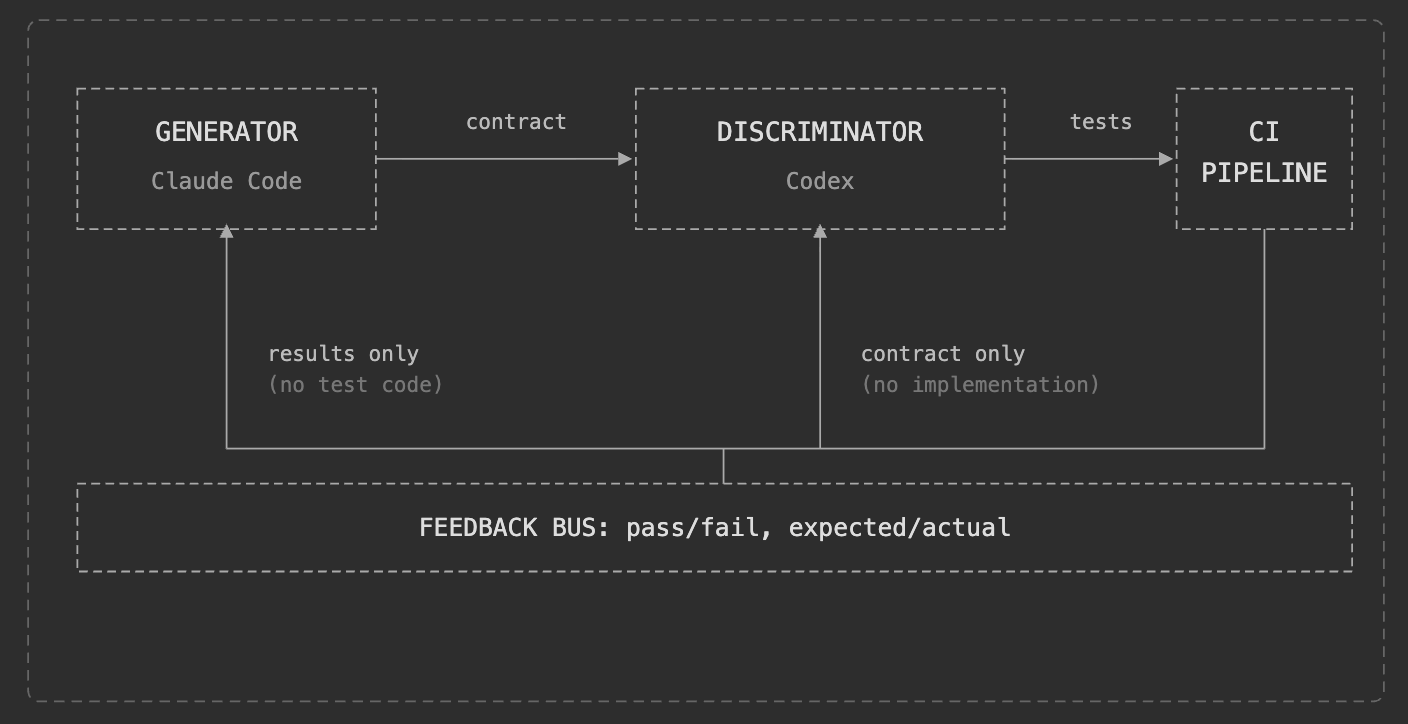
Use different foundational models for generation and verification. Same-vendor models share training biases. Different vendors provide decorrelated failure modes.
GAN failure modes map directly:
Shared context → tautological tests (mode collapse). Tests too shallow → fragile code passes (weak discriminator). Tests too strict → constant thrashing (strong discriminator).
The GAN handles the inner loop: does this code satisfy its spec? But it doesn’t answer: are the specs right? Is the test philosophy calibrated?
The RLHF layer: meta-engineering as preference learning
The outer loop. The human operates on the adversarial cycle, not inside it.

| RLHF Component | Meta-Engineering Equivalent |
|---|---|
| Reward model | Contracts defining “correct” behavior |
| Human preference data | Arbiter decisions on ambiguous failures |
| Policy optimization | Test philosophy adjustments |
A review gate doesn’t improve the system. RLHF does — every arbiter decision updates contracts and test philosophy. The next GAN cycle runs against better specs. The arbiter’s preferences become the system’s definition of quality.
Calibration signals: Too many false positives? Relax the discriminator. Too few failures? Deepen coverage. Frequent ambiguity? Contracts are underspecified — the most valuable signal. Real bugs? System working. Promote to regression.
The industry’s instinct when AI coding fails is to add more human review gates. Gates don’t improve the system. What’s needed is an architecture where verification is structurally independent from generation, and where human judgment systematically improves the machine over time.
Scope: not everything is adversarial
★ = adversarial independence required
Behavioral correctness needs independence. Code quality and design consistency need implementation awareness. Collapsing these layers sacrifices independence where it matters most.
Starting point
- Write contracts for two modules — behavioral descriptions independent of implementation.
- Use a different AI tool (different vendor) to generate tests from contracts only.
- Run tests. Classify failures: real bug, spec gap, or noise.
- Wire it into CI. Review failure distribution weekly. Refine contracts and test philosophy.
Build the machine. Then improve the machine.